 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCF-VLA: Efficient Coarse-to-Fine Action Generation for Vision-Language-Action Policies
Apr 28, 2026Flow-based vision-language-action (VLA) policies offer strong expressivity for action generation, but suffer from a fundamental inefficiency: multi-step inference is required to recover action structure from uninformative Gaussian noise, leading to a poor efficiency-quality trade-off under real-time constraints. We address this issue by rethinking the role of the starting point in generative action modeling. Instead of shortening the sampling trajectory, we propose CF-VLA, a coarse-to-fine two-stage formulation that restructures action generation into a coarse initialization step that constructs an action-aware starting point, followed by a single-step local refinement that corrects residual errors. Concretely, the coarse stage learns a conditional posterior over endpoint velocity to transform Gaussian noise into a structured initialization, while the fine stage performs a fixed-time refinement from this initialization. To stabilize training, we introduce a stepwise strategy that first learns a controlled coarse predictor and then performs joint optimization. Experiments on CALVIN and LIBERO show that our method establishes a strong efficiency-performance frontier under low-NFE (Number of Function Evaluations) regimes: it consistently outperforms existing NFE=2 methods, matches or surpasses the NFE=10 $π_{0.5}$ baseline on several metrics, reduces action sampling latency by 75.4%, and achieves the best average real-robot success rate of 83.0%, outperforming MIP by 19.5 points and $π_{0.5}$ by 4.0 points. These results suggest that structured, coarse-to-fine generation enables both strong performance and efficient inference. Our code is available at https://github.com/EmbodiedAI-RoboTron/CF-VLA.
Reverse Thinking Enhances Missing Information Detection in Large Language Models
Dec 11, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in various reasoning tasks, yet they often struggle with problems involving missing information, exhibiting issues such as incomplete responses, factual errors, and hallucinations. While forward reasoning approaches like Chain-of-Thought (CoT) and Tree-of-Thought (ToT) have shown success in structured problem-solving, they frequently fail to systematically identify and recover omitted information. In this paper, we explore the potential of reverse thinking methodologies to enhance LLMs' performance on missing information detection tasks. Drawing inspiration from recent work on backward reasoning, we propose a novel framework that guides LLMs through reverse thinking to identify necessary conditions and pinpoint missing elements. Our approach transforms the challenging task of missing information identification into a more manageable backward reasoning problem, significantly improving model accuracy. Experimental results demonstrate that our reverse thinking approach achieves substantial performance gains compared to traditional forward reasoning methods, providing a promising direction for enhancing LLMs' logical completeness and reasoning robustness.
EMO: Edge Model Overlays to Scale Model Size in Federated Learning
Apr 01, 2025



Federated Learning (FL) trains machine learning models on edge devices with distributed data. However, the computational and memory limitations of these devices restrict the training of large models using FL. Split Federated Learning (SFL) addresses this challenge by distributing the model across the device and server, but it introduces a tightly coupled data flow, leading to computational bottlenecks and high communication costs. We propose EMO as a solution to enable the training of large models in FL while mitigating the challenges of SFL. EMO introduces Edge Model Overlay(s) between the device and server, enabling the creation of a larger ensemble model without modifying the FL workflow. The key innovation in EMO is Augmented Federated Learning (AFL), which builds an ensemble model by connecting the original (smaller) FL model with model(s) trained in the overlay(s) to facilitate horizontal or vertical scaling. This is accomplished through three key modules: a hierarchical activation replay cache to decouple AFL from FL, a convergence-aware communication controller to optimize communication overhead, and an ensemble inference module. Evaluations on a real-world prototype show that EMO improves accuracy by up to 17.77% compared to FL, and reduces communication costs by up to 7.17x and decreases training time by up to 6.9x compared to SFL.
FLMarket: Enabling Privacy-preserved Pre-training Data Pricing for Federated Learning
Nov 18, 2024



Federated Learning (FL), as a mainstream privacy-preserving machine learning paradigm, offers promising solutions for privacy-critical domains such as healthcare and finance. Although extensive efforts have been dedicated from both academia and industry to improve the vanilla FL, little work focuses on the data pricing mechanism. In contrast to the straightforward in/post-training pricing techniques, we study a more difficult problem of pre-training pricing without direct information from the learning process. We propose FLMarket that integrates a two-stage, auction-based pricing mechanism with a security protocol to address the utility-privacy conflict. Through comprehensive experiments, we show that the client selection according to FLMarket can achieve more than 10% higher accuracy in subsequent FL training compared to state-of-the-art methods. In addition, it outperforms the in-training baseline with more than 2% accuracy increase and 3x run-time speedup.
Orchestrating Development Lifecycle of Machine Learning Based IoT Applications: A Survey
Oct 15, 2019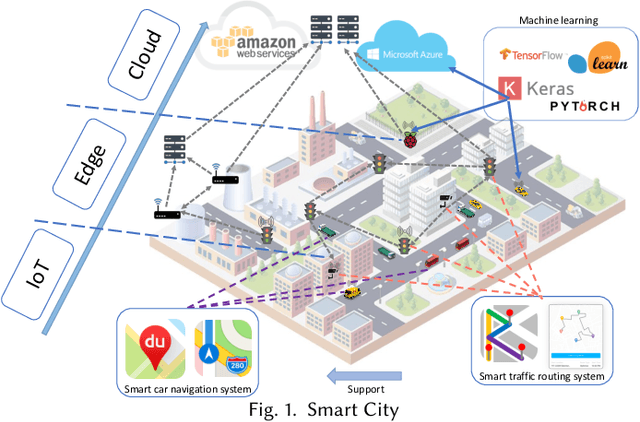
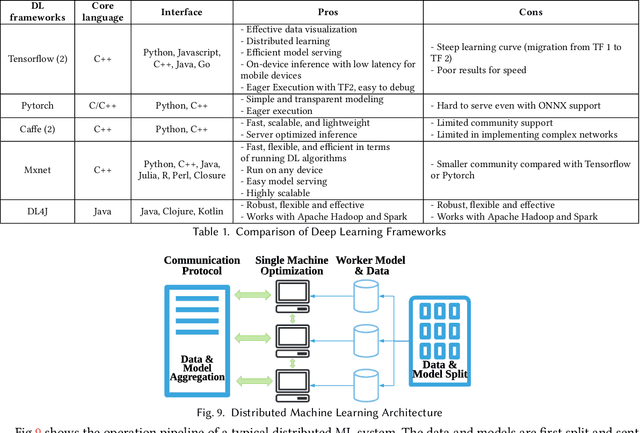
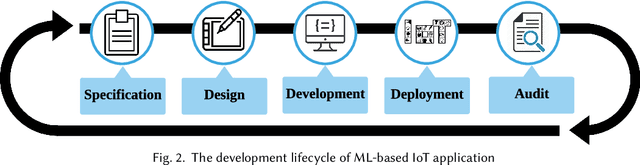

Machine Learning (ML) and Internet of Things (IoT) are complementary advances: ML techniques unlock complete potentials of IoT with intelligence, and IoT applications increasingly feed data collected by sensors into ML models, thereby employing results to improve their business processes and services. Hence, orchestrating ML pipelines that encompasses model training and implication involved in holistic development lifecycle of an IoT application often leads to complex system integration. This paper provides a comprehensive and systematic survey on the development lifecycle of ML-based IoT application. We outline core roadmap and taxonomy, and subsequently assess and compare existing standard techniques used in individual stage.